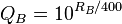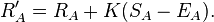この問題に対するほとんどの素朴なアプローチには、いくつかの深刻な問題があります。最悪なのは 、bash.orgとqdb.usの方法です。表示するユーザーは見積もりを上(+1)または下(-1)に投票でき、最良の見積もりのリストは合計ネットスコアで並べ替えられます。これは恐ろしい時間バイアスに悩まされています-古い引用は、たとえわずかにユーモラスであったとしても、単純な長寿によって膨大な数の肯定的な投票を蓄積してきました。このアルゴリズムは、ジョークが年をとるにつれて面白くなった場合に意味があるかもしれませんが、私を信じてください。そうではありません。
これを修正するためのさまざまな試みがあります。期間ごとの賛成票の数の確認、最近の票の重み付け、古い票の減衰システムの実装、賛成票と反対票の比率の計算などです。ほとんどの場合、他の欠陥があります。
最善の解決策は-私が思うに-ウェブサイトTheFunniest The Cutest、The Fairest、およびBest Thingが使用するものです-修正されたコンドルセ投票システム:
システムは、直面したものの中から、通常何パーセントを打つかに基づいて、それぞれに番号を付けます。したがって、それぞれがパーセンテージスコアNumberOfThingsIBeat /(NumberOfThingsIBeat + NumberOfThingsThatBeatMe)を取得します。また、セットの妥当なパーセンテージと比較されるまで、物事はトップリストから除外されます。
セットにコンドルセ勝者がいる場合、このメソッドはそれを見つけます。統計的な性質を考えると、それはありそうもないので、コンドルセの勝者であることに「最も近い」ものを見つけます。
このようなシステムの実装の詳細については、ランク付けされたペアに関するWikipediaページが役立つはずです。
このアルゴリズムでは、2つのオブジェクト(Pick-A-or-Bオプション)を比較する必要がありますが、率直に言って、それは良いことです。人間は抽象的なランキングよりも2つのオブジェクトを比較する方がはるかに優れているということは、決定理論で非常によく受け入れられていると思います。何百万年もの進化のおかげで、私たちは木から最高のリンゴを選ぶのが得意ですが、私たちが選んだリンゴが真のプラトンのリンゴの形にどれだけ近いかを決めるのはひどいです。(ちなみに、これが階層分析法がとても気の利いた理由です...しかし、それは少し話題から外れています。)
最後に、SOはアルゴリズムを使用して最良の回答を見つけます。これは、bash.orgのアルゴリズムを使用して最良の見積もりを見つけるのと非常によく似ています。ここではうまく機能しますが、そこではひどく失敗します。これは主に、古くて評価が高いが、現在は古くなっている回答が編集される可能性があるためです。bash.orgは編集を許可しておらず、たとえ可能であったとしても、現在のインターネットミームに関する10年前のジョークを編集する方法さえ明確ではありません...いずれにせよ、私のポイントは、通常、正しいアルゴリズムであるということです。問題の詳細によって異なります。:-)