チップ内のトランジスタの数を増やすと、速度がどのように向上しますか?
回答:
この種のことについて興味がある場合は、Noam NisanとShimon Schocken 著のThe Elements of Computing(少なくとも前半)を強くお勧めします。手順を終えると、関連する部分を十分に理解した上で、自分の質問に非常に詳しく答えることができます。
コンパニオンのウェブサイトは、実際にいくつかのサンプルの章とノートを持っています。とても親しみやすい本です。自分で問題なく通った後、大学でまったく新しいクラスを受講しました。
簡単な答えは、トランジスタを増やしても残りのトランジスタが速くなるわけではないということですが、期間ごとに1つのことを行う代わりに、2つ(いくつかの制限付き)を行うことができます。
ケンは彼の答えでいくつかの理由をすでにまとめました。さらに拡大する
- より多くのキャッシュRAMより高速な、
明らかに、より大きなキャッシュはより多くのトランジスタを必要とします。しかし、トランジスタが増えると、より高速なキャッシュを使用するという選択肢もあります。CPUキャッシュは単なるSRAMですは、通常6トランジスタ(AKA 6T SRAM)で構成されるです。ただし、十分なトランジスタがある場合は、6つを超えるトランジスタ(8T、10T SRAMなど)からなるより高速で大きいSRAMセルを使用する価値があります。
SIMDだけでなく、あらゆるタイプの高速化命令。たとえば、最近のアーキテクチャには、より高速な暗号化/復号化のためのAESユニット、より良い数学計算(特にデジタル信号処理)のためのFMA、またはより高速な仮想マシンのための仮想化がよくあります。より多くの命令をサポートすることは、それらをデコードして実行するためにより多くのリソースが必要であることを意味します
これらはかなり明確です
過去にはFPUに十分なダイ領域がなかったため、浮動小数点演算の要件が高い場合は、別のダイ領域を購入する必要があります。トランジスタ数が大幅に増えると、FPUを組み込み、浮動小数点演算を大幅に高速化できます。
さらに、最近のCPUはスーパースカラーであり、命令ストリームが線形でシリアルであっても、独立したデータ片を見つけてそれらをより早く計算することにより、一度に複数のことを実行しようとします。彼らが並行してできることが多ければ多いほど、彼らはより速くなります。そのために、CPUは複数のALUを持つことができ、ALUは複数の実行ユニットを持つことができます。たとえば、CPUに前の世代の4と比較して5つの加算器がある場合、クロックを変更することなく、最も楽観的な状況ですでに25%速く実行されています。より洗練されたCPU は、順不同の実行さえ採用します(これは、ほとんどの最新の高性能CPUの場合です)。
- より洗練された分岐予測ロジックなど、より優れた処理ロジック
操作は通常、さまざまな方法で実行できます。より多くのトランジスタがある場合、より高速な手法を使用するためのより多くのリソースがあります。いくつかの簡単な例:
ビットシフト:
添加:
- 単純な加算器も、全加算器を直列に接続することによって作成されます。このように、Nビット加算器は、そのジョブを完了するためにNクロックを必要としますが、これは確かにCPUで期待されていることではありません。
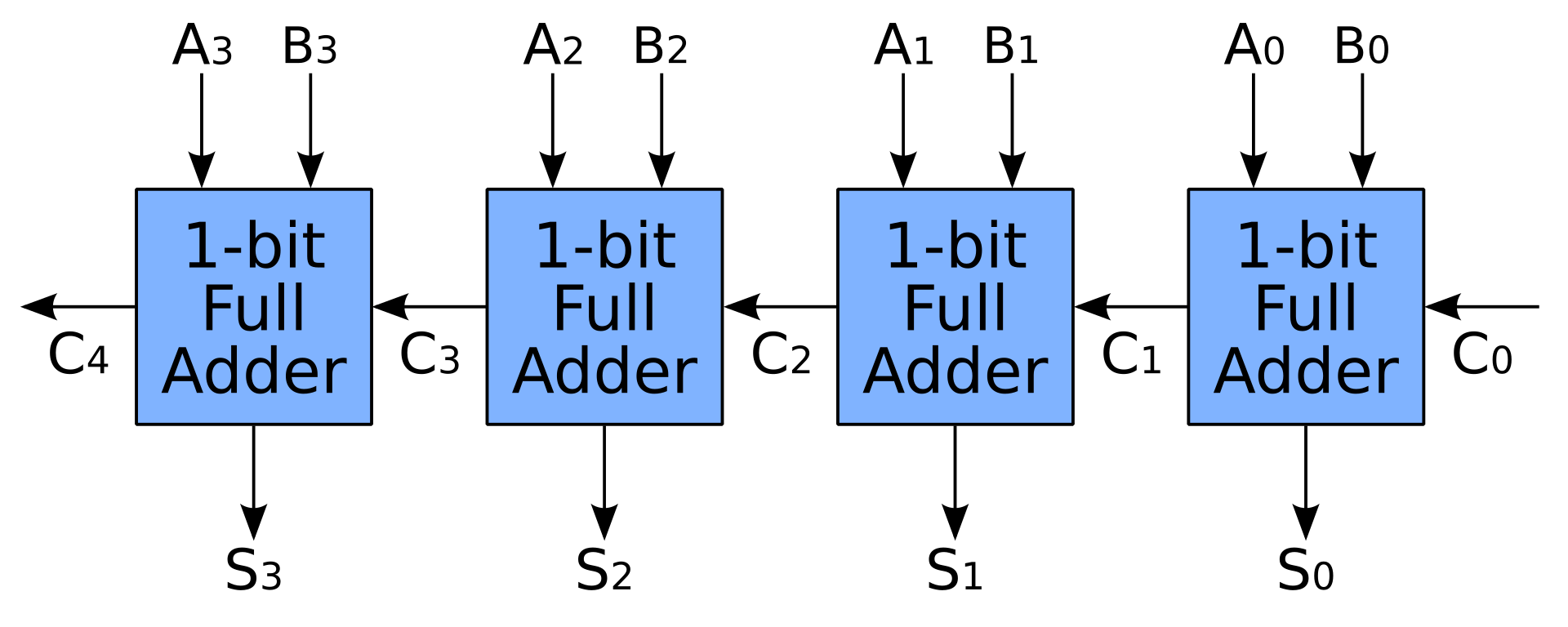
- より多くのトランジスタを使用して、キャリールックアヘッドまたはキャリーセーブ加算器でキャリーを事前計算することにより、加算を高速化できます。全加算器は引き続き使用されますが、キャリー事前計算ユニットにはさらに多くのスペースが必要です
- 単純な加算器も、全加算器を直列に接続することによって作成されます。このように、Nビット加算器は、そのジョブを完了するためにNクロックを必要としますが、これは確かにCPUで期待されていることではありません。

#/media/File:1-bit_full-adder.svg)
同じことは、乗算器、除算器、スケジューラなどの他のユニットにも当てはまります。たとえば、組み合わせロジックを使用すると、単一のクロックで非常に高速に乗算を実行できます。3ビット乗算器の質問でいくつかの簡単な例を見ることができます-それらはどのように機能しますか?。しかし、必要なトランジスタは入力幅の2乗に成長するため、乗算器を備えた小さなCPUは、代わりに順次ロジックを使用して、乗算器のための多くのスペースを節約します。
古い乗算器アーキテクチャでは、シフターとアキュムレーターを使用して各部分積を加算し、多くの場合、サイクルごとに1つの部分積を合計し、ダイ領域の速度とトレードオフしました。最新の乗算器アーキテクチャは、(変更された)Baugh–Wooleyアルゴリズム、Wallaceツリー、またはDadda乗算器を使用して、単一のサイクルで部分積を加算します。ウォレスツリーの実装のパフォーマンスは、2つの被乗数の1つを変更したブースをエンコードすることで改善されることがあり、合計する必要がある部分積の数を減らします。
https://en.wikipedia.org/wiki/Binary_multiplier#Implementations
トランジスタの巨大なプールができたら、組み合わせロジックを使用して、乗算器よりもはるかにリソースを消費するFMAを実行することもできます。
最近のコンピュータには、組み合わせロジックで実装された乗算器と、その後に続く加算器と結果を格納するアキュムレータレジスタで構成される専用MACが含まれている場合があります。レジスタの出力は加算器の1つの入力にフィードバックされるため、各クロックサイクルで乗算器の出力がレジスタに追加されます。組み合わせ乗算器は大量のロジックを必要としますが、以前のコンピュータの典型的なシフトおよび追加の方法よりもはるかに迅速に積を計算できます。