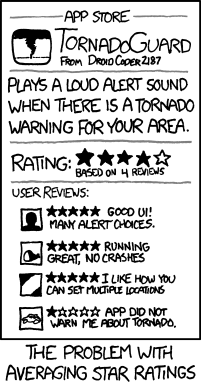
私が正しく理解していれば、1-5のスケールでの本の評価はリッカートスコアです。つまり、私にとって3は、他の誰かにとって必ずしも3であるとは限りません。これは通常のスケールのIMOです。順序スケールを実際に平均するべきではありませんが、モード、中央値、パーセンタイルを確実に取ることができます。
人口の大部分が上記の統計よりも平均を理解しているので、ルールを曲げることは「大丈夫」ですか?研究コミュニティは、リッカートスケールベースのデータの平均を取ることを強く非難しますが、大衆でこれを行うことは問題ありません(実際に言えば)?この場合の平均を取ることは、そもそも誤解を招くかもしれませんか?
Amazonのような会社が基本的な統計情報を手探りすることはまずないと思われますが、そうでない場合は、ここで何が欠けていますか?順序尺度は、平均を取ることを正当化するための順序の便利な近似であると主張できますか?どんな理由で?
3
あなたのための3が他の誰かのための3と同じでない場合、スケールさえありません:あなたは比類のない測定値のコレクションを持っており、それらを要約するためにできることはほとんど意味がありません。スケールを序数にしているのは、(a)値を比較できるため、3とmy 3は同じことを意味しますが、(b)値の数値の違いはその符号を除いて意味がないため、(たとえば)2つの3 4と2、または5と1は任意の順序で並べることができますが、評価の各ペアの数値は平均と中央値が同じです。
—
whuber
@whuber-しかし、2人が数字について1-9の尺度で同じ意見を共有しないかもしれないというのは本当ではありませんか?私にとっての6は、他の誰かが事前に定義されたスケールを持っていない限り、実際には6ではないかもしれません。
—
PhD
アマゾンで最近、あるレビューを読みました。「素晴らしい製品はそれに失敗することはありません。5つ星を与えることはないので、4を獲得しました」。これが平均をゆがめない場合、私はそれがわからない
—
マットウィルコ
@Wilko規模の違いではなく、意見の違いについて話している。(たとえば)体操やフィギュアスケートのスコアリング、または川の急流の難易度を評価するための国際的なスケールのように、スケールが非常に慎重に較正されている場合でも、専門家がそのスケールを使用するように訓練されている場合でも、ばらつきがあります。それは通常、スケールが主観的であるという証拠として解釈されません。それは裁判官間の変動として解釈されます。
—
whuber
申し訳ありませんが、これは実際には答えではありませんが、残念ながら「コメント」機能が見つかりませんでした。最近、私は顧客レビューの重要な要素に関する修士論文を書き始めました。次の状況を考慮して、私はAmazonの5つ星評価システムの重要性も疑い始めました。- 信頼できないレビューの数- 評価バイアスとJカーブの影響(buildingreputation.com/writings/2009
—
derPio