私は、k分割(および1つを残す)交差検証の利点、およびトレーニングセットを分割して3番目のホールドアウト「検証」セットを作成する利点をよく知っています。ハイパーパラメータの選択に基づいてパフォーマンスをモデル化するため、それらを最適化および調整し、実際のテストセットで最終的に評価するために最適なものを選択できます。これらの両方をさまざまなデータセットに個別に実装しました。
ただし、これらの2つのプロセスを統合する方法は正確にはわかりません。私はそれができることを確かに知っています(入れ子にされた相互検証、そうですか?)、私は人々がそれを説明するのを見ましたが、プロセスの詳細を実際に理解したほど十分に詳細ではありません。
分割とループの正確な実行が明確ではないが、このプロセス(このような)をほのめかしている興味深いグラフィックスのページがあります。ここで、4番目は明らかに私がやりたいことですが、プロセスは不明確です。
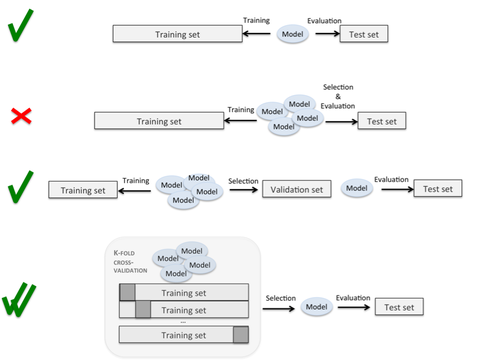
このサイトには以前の質問がありますが、それらは検証セットをテストセットから分離することの重要性を概説していますが、どれもこれを実行する正確な手順を指定していません。
それは次のようなものですか?k個のフォールドごとに、そのフォールドをテストセットとして扱い、別のフォールドを検証セットとして扱い、残りをトレーニングしますか?これは、データセット全体をk * k回繰り返す必要があるようです。そのため、各フォールドは、少なくとも1回はトレーニング、テスト、および検証として使用されます。入れ子の交差検証は、k分割のそれぞれの中でテスト/検証分割を行うことを意味するようですが、特にkが高い場合、これは効果的なパラメーター調整を可能にするのに十分なデータではありません。
(事前に指定しないように)パラメータ調整を実行しながら、k分割交差検証(最終的にすべてのデータポイントをテストケースとして扱うことができる)を可能にするループと分割の詳細な説明を提供して、誰かが私を助けてくれませんかモデルパラメータ、および代わりに別のホールドアウトセットで最高のパフォーマンスを発揮するパラメータを選択しますか?)