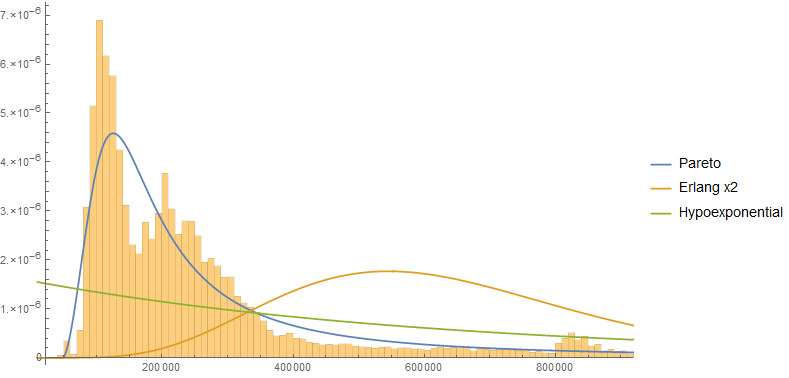
サーブレットベースのアプリケーションがあり、そのサーブレットへの各リクエストを完了するのにかかる時間を測定しています。平均値や最大値などの単純な統計をすでに計算しています。ただし、さらに洗練された分析を作成したいので、これらの応答時間を適切にモデル化する必要があると思います。
確かに、応答時間はよく知られた分布に従うので、その分布が正しいモデルであると信じるのには十分な理由があります。しかし、この分布がどうあるべきかはわかりません。
対数正規とガンマが思い浮かび、実際の応答時間データのいずれかの種類を適合させることができます。応答時間はどの分布に従うべきかについて誰かが考えていますか?