この質問は、ロジスティックモデルで十分かどうかを判断する方法に関する実際の混乱から生じています。従属変数として形成されてから2年後に、個々のプロジェクトのペアの状態を使用するモデルがあります。結果は成功(1)または失敗(0)です。ペアの形成時に測定された独立変数があります。私の目的は、私が仮定した変数がペアの成功に影響を与えるかどうかをテストし、その成功に影響を与え、他の潜在的な影響を制御することです。モデルでは、対象の変数は重要です。
モデルはのglm()関数を使用して推定されましたR。モデルの品質を評価するために、私はいくつかのことを行っている:glm()あなたは与えresidual deviance、AICそしてBICデフォルトで。さらに、モデルのエラー率を計算し、ビン化された残差をプロットしました。
- 完全なモデルは、私が推定した(および完全なモデルにネストされている)他のモデルよりも小さい残差、AICおよびBICを持っているため、このモデルは他のモデルよりも「優れている」と思います。
- モデルのエラー率はかなり低く、IMHO(Gelman and Hill、2007、pp.99のように):、
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)約20%です。
ここまでは順調ですね。しかし、ビン化された残差をプロットすると(再びGelman and Hillのアドバイスに従って)、ビンの大部分が95%CIの範囲外になります。
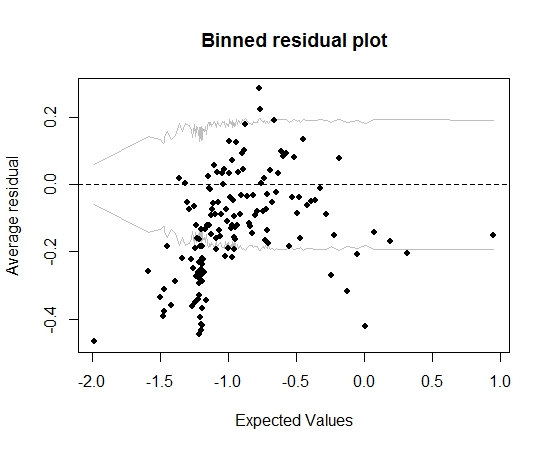
このプロットは、モデルにまったく問題があると思うように導きます。それはモデルを捨てることに私を導くべきですか?モデルが不完全であることを認める必要がありますが、それを維持し、対象変数の効果を解釈する必要がありますか?ビン化された残差プロットを実際に改善することなく、変数を順番に除外し、変換も試行錯誤しました。
編集:
- 現時点では、モデルには多数の予測子と5つの相互作用効果があります。
- これらのペアは、すべてが短時間で形成されるという意味で(ただし、厳密に言えば、すべて同時にではない)という意味で互いに「比較的」独立しており、多数のプロジェクト(13k)と多数の個人(19k )そのため、かなりの割合のプロジェクトには1人の個人しか参加していません(約20000ペアあります)。
2
あなたの言うことを基にすると、サンプルサイズは問題ではないようです。なぜなら、私には約2000万ペア(うち約20%が成功している)があるからです。
—
アントワーヌヴェルネ