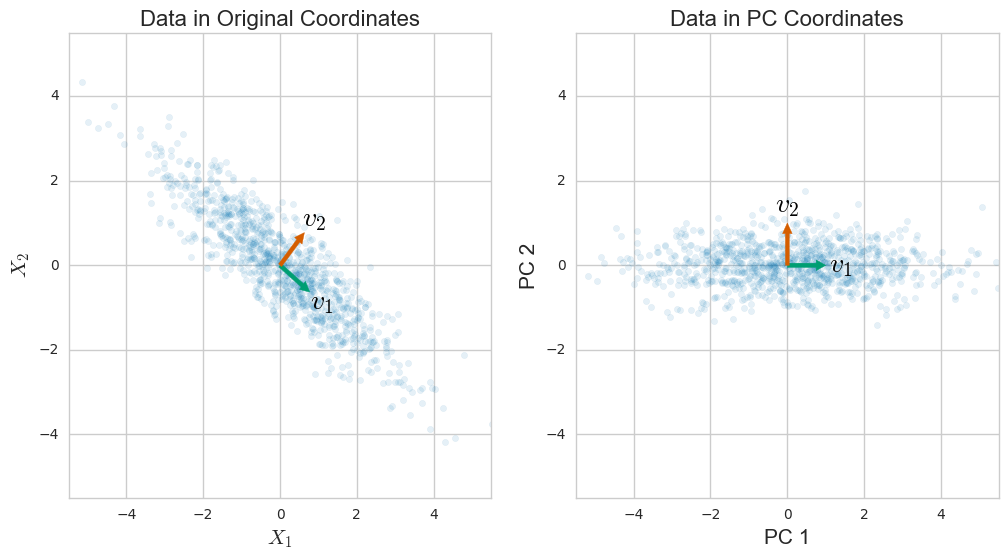
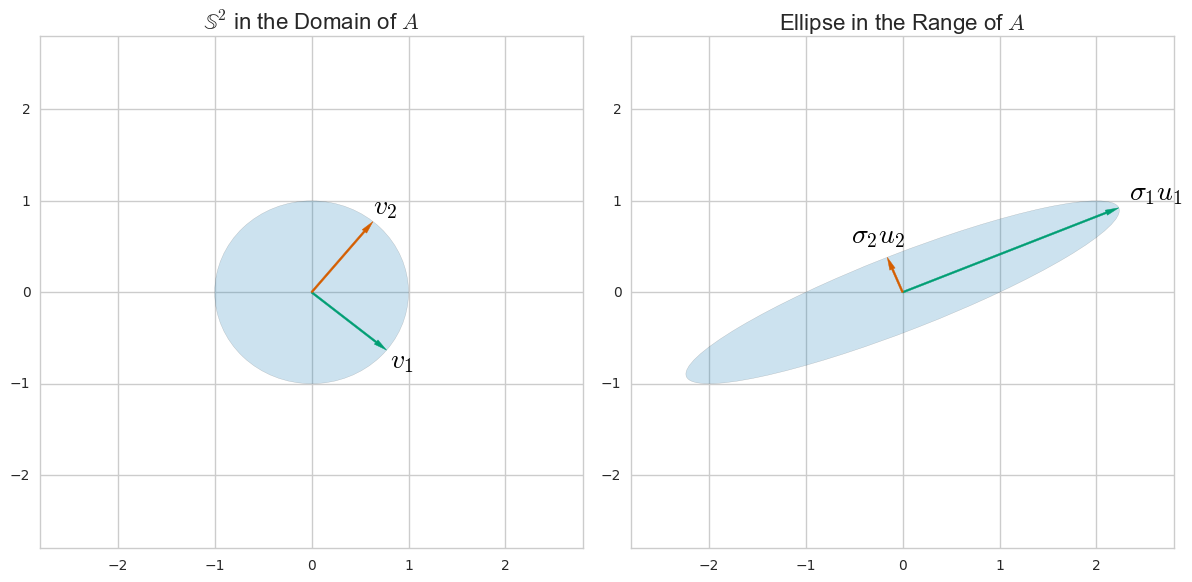
主成分分析(PCA)は通常、共分散行列の固有分解によって説明されます。ただし、データ行列特異値分解(SVD)を介して実行することもできます。どのように機能しますか?これら2つのアプローチの関係は何ですか?SVDとPCAの関係は何ですか?
または、言い換えると、データ行列のSVDを使用して次元削減を実行する方法ですか?
8
このFAQスタイルの質問は、さまざまな形式で頻繁に尋ねられるため、自分の回答と一緒に書きましたが、正規のスレッドがないため、重複を閉じるのは困難です。この付随するメタスレッドでメタコメントを提供してください。
—
アメーバ
PCAはSVDの特殊なケースです。PCAは、理想的には同じ単位のデータを正規化する必要があります。行列はPCAのnxnです。
—
オーヴァーコルヴァー
@OrvarKorvar:あなたは何のnxn行列について話しているのですか?
—
Cbhihe