あなたが知っている最もあいまいなソートアルゴリズムは何ですか?[閉まっている]
回答:
スローソートは、(分割して征服するのではなく)乗算して降伏することで機能します。興味深いのは、それが構築可能な最も効率の低いソートアルゴリズムであるためです(漸近的に、そしてそのようなアルゴリズムは遅いものの、常に結果に向かって動作しなければならないという制限があります)。
最良の場合、bogosortは非常に効率的です。つまり、配列が既にソートされているためです。スローソートは、このような最高の動作から「苦しむ」ことはありません。でもその最良の場合には、それはまだランタイム持つ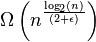 ためのε > 0を。
ためのε > 0を。
ドイツ語版ウィキペディアの記事から改編した擬似コードは次のとおりです。
function slowsort(A, i, j):
if i >= j: return
m = (i + j) / 2
slowsort(A, i, m)
slowsort(A, m + 1, j)
if A[j] < A[m]:
swap(A[j], A[m])
slowsort(A, i, j - 1)
これがあいまいなものとしてカウントされるかどうかはわかりませんが、最もばかげたソート「アルゴリズム」の1つはBogosortです。Bogosortページ以外のリンクも楽しいです。
そして、「quantum bogo-sort」のセクションからこの逸品があります。
おそらく、2 Nユニバースの作成も非常にメモリ集約型です。
うーん...あなたはそれを言うことができます:-)。
もう1つのあいまいな「アルゴリズム」はインテリジェントデザインソートです。ただし、アルゴリズムが高速化されていないか、メモリ消費量が少ないアルゴリズムはありません。
私のデータ構造クラスでは、(明示的に)Stooge sortの正確性を証明する必要がありました。実行時間はO(n ^ {log 3 / log 1.5})= O(n ^ 2.7095 ...)です。
オリジナルのKnuthの本の1つである「並べ替えと検索」には、ハードディスクを使用せずにテープファイルをソートするプロセスを図式化した中間の展開がありました。6台のテープドライブを使用し、各ドライブが順方向、逆方向、巻き戻し、またはアイドル状態のときを明示的に示したと思います。今日、それは時代遅れの技術の記念碑です。
私はかつて、CRAYアセンブラーでベクターレジスタのバブルソートを行いました。マシンにはダブルシフト命令があり、ベクトルレジスタの内容を1ワードずつ上下にシフトできました。1つおきのポイントを2つのベクトルレジスタに入れると、完了するまで別のメモリ参照を行う必要なく、完全なバブルソートを実行できます。バブルソートのN ** 2の性質を除けば、効率的でした。
また、単一のソートで可能な限り高速に長さ4のベクトルの浮動小数点ソートを実行する必要がありました。テーブルルックアップでそれをしました(A2-A1の符号ビットは1ビットで、A3-A1の符号は別のビットを形成します...そして、テーブル内の順列ベクトルを検索します。実際に私が思いつく最も速い解決策でした。 with。しかし、現代のアーキテクチャではうまく機能せず、浮動ユニットと整数ユニットがあまりにも分離されています。
Google Code JamにはGorosortと呼ばれるアルゴリズムに関する問題がありましたが、彼らはこの問題のために発明したと思います。
五郎には4本の腕があります。五郎はとても強いです。あなたはゴロを台無しにしないでください。Goroは、N個の異なる整数の配列をソートする必要があります。アルゴリズムはGoroの強みではありません。強さは五郎の強さです。Goroの計画では、2本の手の指を使ってアレイのいくつかの要素を押さえ、3番目と4番目の拳でテーブルをできるだけ強く打ちます。これにより、配列の保護されていない要素が空中に飛び出し、ランダムにシャッフルされ、空の配列位置にフォールバックします。
http://code.google.com/codejam/contest/dashboard?c=975485#s=p3
名前を覚えてはいけませんが、基本的には
while Array not sorted
rearrange the array in a random order
シェルソート
アルゴリズム自体はそれほど曖昧ではないかもしれませんが、実際に実際に使用されている実装に名前を付けることができるのは誰ですか?できます!
TIGCC(TI-89 / 92 / V200グラフ電卓用のGCCベースのコンパイラ)はqsort、その標準ライブラリでの実装にシェルソートを使用します。
__ATTR_LIB_C__ void qsort(void *list, short num_items, short size, compare_t cmp_func)
{
unsigned short gap,byte_gap,i,j;
char *p,*a,*b,temp;
for (gap=((unsigned short)num_items)>>1; gap>0; gap>>=1) // Yes, this is not a quicksort,
{ // but works fast enough...
byte_gap=gap*(unsigned short)size;
for(i=byte_gap; i<((unsigned short)num_items)*(unsigned short)size; i+=size)
for(p=(char*)list+i-byte_gap; p>=(char*)list; p-= byte_gap)
{
a=p; b=p+byte_gap;
if(cmp_func(a,b)<=0) break;
for(j=size;j;j--)
temp=*a, *a++=*b, *b++=temp;
}
}
}
コードサイズを低く抑えるために、クイックソートを優先してシェルソートが選択されました。漸近的な複雑さはさらに悪化しますが、TI-89にはRAM(190Kからプログラムサイズとアーカイブされていない変数の合計サイズを引いたもの)の多くのRAMがないため、アイテムの数は低くなります。
私が書いているプログラムでは遅すぎると不平を言った後、より速い実装が書かれました。アセンブリの最適化とともに、より良いギャップサイズを使用します。ここにあります:qsort.c