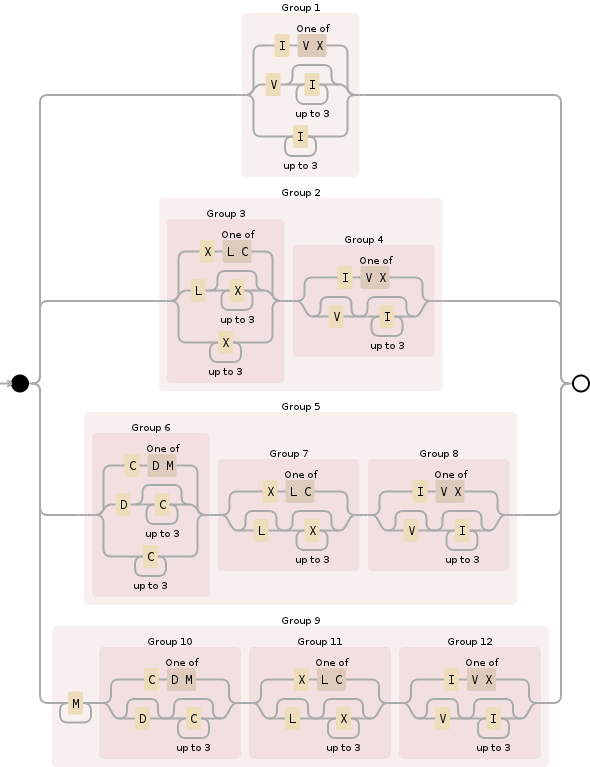
これには次の正規表現を使用できます。
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
それを破壊、M{0,4}数千人のセクションを指定し、基本的に間にそれを抑制する0と4000。それは比較的簡単です:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
もちろん、より大きな数を許可する場合は、数千の任意の数(ゼロを含む)M*を許可するようなものを使用できます。
次は(CM|CD|D?C{0,3})、少し複雑ですが、これは何百ものセクションのためのものであり、すべての可能性をカバーしています:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
3番目に、(XC|XL|L?X{0,3})前のセクションと同じルールに従いますが、10の位についてです。
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
そして最後に(IX|IV|V?I{0,3})、ユニットセクションは前の2つのセクションと同様に処理さ0れ9ます(奇妙に見えるにもかかわらず、ローマ数字は、それらが何であるかを理解したら、いくつかの論理的なルールに従います)。
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
この正規表現は空の文字列にも一致することに注意してください。これを望まない場合(そして正規表現エンジンが十分に最新である場合)、肯定的な後読みと先読みを使用できます。
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(他の選択肢は、長さがゼロでないことを事前に確認することです)。