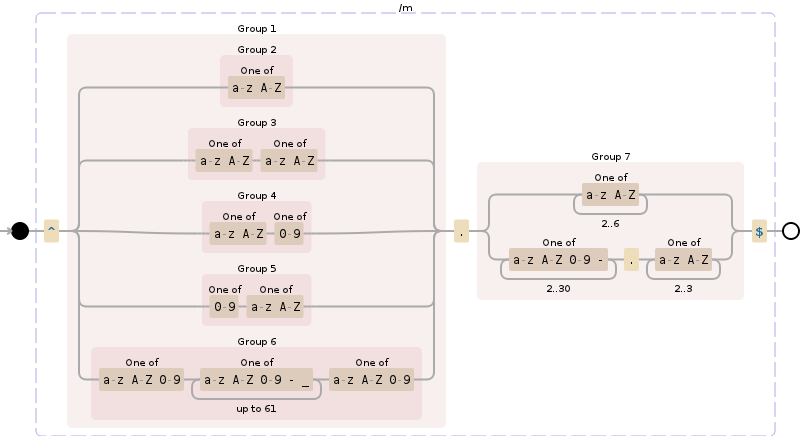
ドメイン名を検証する必要があります:
Google COM
stackoverflow.com
つまり、最も生の形式のドメイン-wwwのようなサブドメインでさえも。
- 文字はa〜zのみにする必要があります。AZ | 0-9およびピリオド(。)およびダッシュ(-)
- ドメイン名の部分はダッシュ(-)で開始または終了しないでください(例-google-.com)
- ドメイン名の部分は1〜63文字である必要があります
拡張子(TLD)は今のところ#1ルールの下であれば何でもかまいませんが、後でリストに対して検証することができますが、1文字以上にする必要があります
編集:TLDは現状では明らかに2〜6文字です
番号。4改訂: TLDは.co.ukのようなものを含むため、実際には「サブドメイン」とラベル付けする必要があります-(リストに対するチェックを除いて)可能な唯一の検証は「最初のドットの後に1つまたはルール#1の下でより多くの文字
どうもありがとうございました。
1
まったく役に立たないかもしれません。google.co.ukと一部の日本語ドメインに関しては、正規表現を使用する前によく考えなければならないことでしょう。私の個人的な考えは、正規表現はドメインを実際のドメインに検証するのに十分ではないということです。参考までに、TLD
—
SO
しばしば忘れられる:完全修飾ドメイン名の場合、TLDの後のピリオドと一致する必要があります。
—
schmijos 2013年
4年が経過しましたが、現在の数は最大89,000です
—
mydoglixu