データサイエンスは機械学習とどのように関連していますか?
回答:
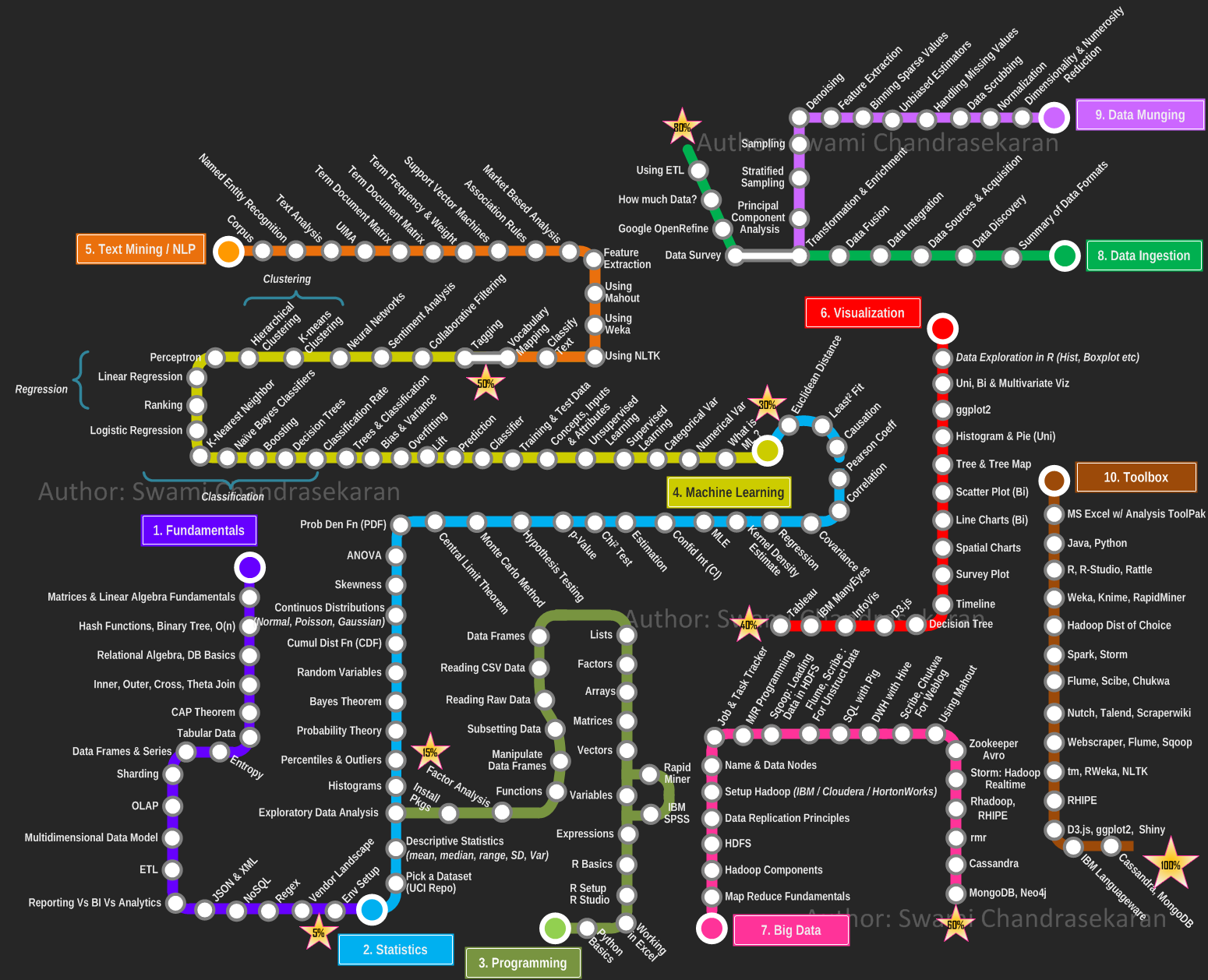
データサイエンスは、機械学習よりもはるかに広い概念です。それは、洞察を得るための単純なデータ視覚化と記述統計から始まり、データを準備するためのクレンジングのような操作です。いくつかのMLアルゴリズムを使用する前に。
基本的に、ビッグデータ、視覚化、データ前処理などの巨大なスタックは、機械学習の範囲外です。そして、それらはすべて「データサイエンス」の不可欠な部分です。
大きな解像度の画像:https : //whatsthebigdata.files.wordpress.com/2013/07/datascientistmap.png
機械学習は、データから学習できるシステムを作成しようとします。そのため、さまざまな設定で使用できます。たとえば、ロボットに仮想エージェントの歩行やトレーニングを学習させ、ビデオゲームをプレイさせることができます。
データサイエンスは、データからの知識の抽出に関係しています。そのためには、さまざまな分野のさまざまなテクニックを使用します。機械学習には、ディープラーニング、決定木、さまざまなクラスタリングアルゴリズムなど、データサイエンティストに非常に役立ついくつかの手法が含まれています。ただし、機械学習はデータサイエンスが使用する以上のものを提供し、データサイエンスは機械学習だけに依存するわけではありません。
データサイエンスははるかに広範です。それは、現在、正直に言って非常に明確な定義を持っていないキャッチオール用語のようなものです。しかし、データサイエンスには、高速(すぐに到着します)、ボリューム(多くあります)、または変動性(自然言語処理のように乱雑です)のデータを理解するために必要なすべてのスキルとテクニックが含まれています。つまり、機械学習とAIは確かに含まれますが、SQL、Hadoop、Sparkなどの実際の状況で使用できるツール(および並列プログラミングの知識などの関連情報)も含まれます。さらに、データサイエンスには、優れたグラフの作成やExcelの使用などのコミュニケーションの側面が含まれる場合と含まれない場合があります。
基本的に、データサイエンスはML +です。
他の人が指摘したように、データサイエンスは機械学習よりもはるかに広い用語です。機械学習技術の適用は、データサイエンスの1つの側面です。データサイエンスは、より一般的には、データから知識を引き出す科学です。この用語は1960年に造語され、問題の定義、データ収集、データ変換、データモデリング/分析、意思決定の流れと相互作用を説明するために進化し続けました。だからあなたの質問に具体的に答えるには:
- 機械学習は、データモデリング/分析(機械学習アルゴリズムのトレーニングによる)、意思決定(ストリーミング、オンライン学習、すべて機械学習のトピックであるリアルタイムテストによる)のためのアルゴリズムを提供することにより、データサイエンスを支援します。データの準備さえも(機械学習アルゴリズムがデータの異常を自動的に検出します)。
- データサイエンスは、機械学習から引き出されたアイデア/アルゴリズムの束をつなぎ合わせてソリューションを作成します。その際、従来の統計、ドメインの専門知識、および基本的な数学から多くのアイデアを借ります。このように、データサイエンスはユースケースを解決するプロセスであり、ソリューションの重要な歯車である機械学習とは対照的にソリューションを提供します。